N2V2¶
Overview¶
N2V2 [1] is a self-supervised denoising method based on Noise2Void [2,3]. The method was developed to remove pixel-noises from images without leaving unwanted checkerboard artefacts which can occasionally happen with Noise2Void.
It retains the same training scheme (i.e. training on noisy images by randomly masking pixels), and differs from Noise2Void by the network architecture and pixel masking procedure. More specifically, N2V2 removes the first skip connection and introduces max blurpool layers in the UNet model [4], and the N2V2 masking scheme uses the median of each local image patch as replacement/masking value, rather than a randomly chosen neighboring pixel intensity.
Checkerboard artefacts¶
Checkerboard artefacts [1] sometimes occur with Noise2Void. This effect is most prominent in the presence of salt and pepper noise or hot pixels in sCMOS cameras. They appear as little crosses, as illustrated in the figure below.

Fig 1.: Checkerboard artefacts. The figure shows a noisy image crop (left), a noisy close-up (center) and the corresponding Noise2Void prediction (right). While the denoising was effective, a distinctive checkerboard pattern appears nonetheless in the Noise2Void prediction. CC-BY.
Noise2Void vs N2V2¶
Changes to the architecture¶
The model architecture used in Noise2Void and its siblings (N2V2, structN2V, P(P)N2V etc.) is a UNet model [4], a fully convolutional architecture. Its main parts are an encoder, which downsamples and compresses the information into a bottleneck, and a decoder, which upsamples the information back to the original image size (see figure 2).
In order to compress the information, the UNet architecture can perform multiple downsampling operations, defining multiple levels of spatial resolution. For each downsampling operation in the encoder, there is a corresponding upsampling operation in the decoder.
One of the trick of the UNet architecture is to use skip connections between the encoder and the decoder. These skip connections allow the decoder to access the information from the encoder at the same spatial resolution. This is often useful to recover fine details of the image.
N2V2 changes the architecture used in Noise2Void in two ways: the top skip connection is removed, and the downsampling is done using a different operation.
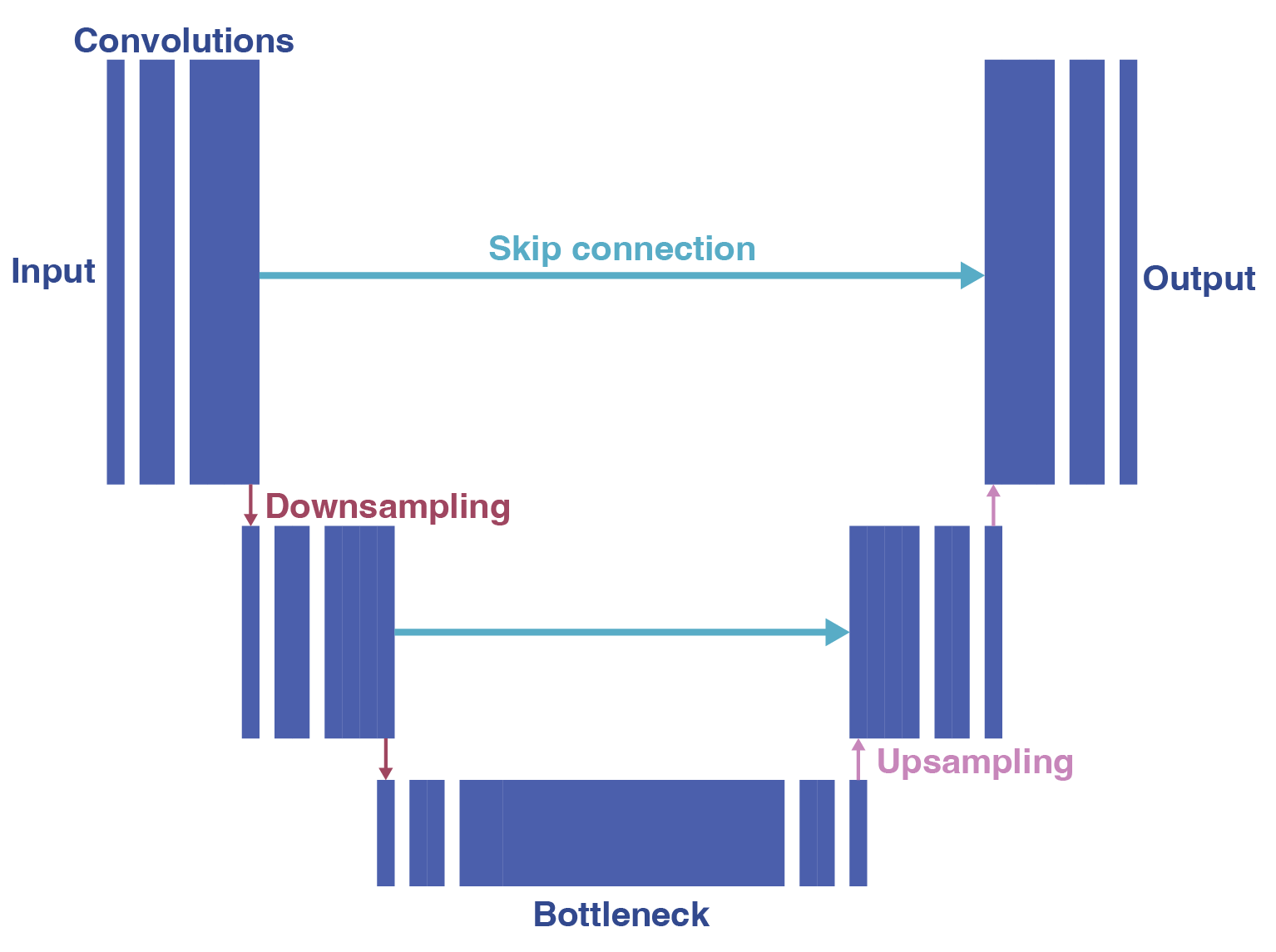
Fig 2.: UNet architecture as used by Noise2Void. CC-BY.
Skip connections¶
In N2V2, the first skip connection is removed to constrain the among of high-frequency information that can be passed from the encoder to the decoder. Since the checkerboard artefacts are high-frequency artefacts, this change is expected to reduce their occurrence.
Max blur pooling layers¶
The second change is the introduction of max blur pooling as downsampling layers in the encoder to avoid aliasing-related artefacts, as opposed to the max pool layer used in Noise2Void. As with Noise2Void, the downsampling step starts from computing the maximum value in the patch (i.e. the region over which the filter is applied for each pixel), before applying a blur kernel (which is a convolutional operation) [5]. Since the output is smoothed, sharp transitions between pixel values are avoided and the aliasing artefacts are reduced.

Fig 3.: Max pool vs max blur pool downsampling. An input (left) is passed through a max pool layer (center) and through a max blur pool layer (right) for comparison. The blur pool layer introduces blurring, avoiding aliasing-related artefacts. CC-BY.
Changes to the masking scheme¶
In Noise2Void, the masking scheme consists in replacing central pixels by a randomly chosen neighboring pixel (see the example). N2V2 changes the strategy for pixel selection by replacing the central pixel with the median of the neighborhood. This leads to a masking with a lower difference between masked pixels and their surrounding, preventing aliasing artefacts arising from sharp transitions between masked and unmasked pixels.

Fig 4.: Noise2Void vs N2V2 manipulation. In both algorithms, randomly selected pixels in the input patch (left) are selected and their value replaced. Noise2Void (center) replaces the values by the value of one of the neighboring pixel, while N2V2 (right) uses the median of the neighborhood. CC-BY.
Comparison¶
These changes allow suppression of the checkerboard artefacts, as illustrated in the figure below. N2V2 does not take longer than Noise2Void to train, and you can easily compare the results of both methods.
To train Noise2Void and N2V2 on the same dataset, refer to their respective examples: SEM Noise2Void and SEM N2V2.

Fig 5.: Noise2Void vs N2V2 in the presence of checkerboard artefacts. The figure shows a noisy image crop (left), the Noise2Void prediction of the region delimited by a red square (center) and the corresponding N2V2 prediction (right). The cherckerboard artefacts are clearly visible in the Noise2Void prediction (center), while they are much less severe with N2V2 (left). CC-BY.
Limitations¶
Beyond the checkerboard artefacts, N2V2 suffers from the same limitations as Noise2Void regarding pixel-wise independent noise.
References¶
[1] Eva Höck, Tim-Oliver Buchholz, Anselm Brachmann, Florian Jug, and Alexander Freytag. "N2V2 - Fixing Noise2Void Checkerboard Artifacts with Modified Sampling Strategies and a Tweaked Network Architecture." ECCV, 2022. link
[2] Alexander Krull, Tim-Oliver Buchholz, and Florian Jug. "Noise2Void - learning denoising from single noisy images." CVPR, 2019. link
[3] Joshua Batson, and Loic Royer. "Noise2Self: Blind denoising by self-supervision." MLR, 2019. link
[4] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." MICCAI, 2015. link
[5] Richard Zhang. "Making convolutional networks shift-invariant again." MLR, 2019. link